Introduction to Object Centric Learning

Most of the times CNNs (Convolution Neural Networks) are about Image Classification or Segmentation. The Objective of this Article is to introduce a new growing paradigm to learn meaningful features from an image compatible with object learning of babies (0–2 yrs.) which is called Object Centric Learning.
What is Object Centric Learning?
The assumption of Object Centric Learning models is very simple: they assume that the image is composed by K different objects (including the background).
The model is trained in an unsupervised fashion to identify K different objects, therefore combined into a image (“reconstructed image”) to optimize the model using the difference between the input image and the reconstructed image

Input and Output
The input of this model is just an image while the output are:
- the reconstructed objects, a set of K images containing the objects
- K masks where the i-th mask tells which pixels belong to the i-th object
- A latent space for every object (i.e. a vector of numbers) which can be used for downstream tasks like object properties classification or use all the latent spaces combined to estimate global image features like if the image is a number between 0 and 9 (like MNIST dataset).

Datasets
Typically Object Centric Learning datasets are very simple in the sense of the object shapes inside the images. Furthermore, objects have a very distinct color compared to the background to be easily identifiable.





Metrics
An hard and intriguing part is the choose of the metric i.e. the function that establish the goodness of our Object Centric Learner (from now on OCL). I’ve said hard because compared to other model categories like image classifier or generators (where you can use accuracy, f1 score or log likelihood) the metric of a OCL has to be permutation invariant because the order in which our Object Centric Learner finds the object could not be the same of the dataset but any order is fine as long the OCL finds the Objects.
For example if our model finds in this order {cube, sphere, background} the metric should be the same if the model finds in this order {background, cube, sphere} even if in the dataset the order is {sphere, background, cube}.
ARI
A popular permuation invariant metric used in OCL models is ARI (Adjusted Rand Index) which is originally introduced for Clustering comparison but now also used to compare the Object true masks with the Object predicted masks from the model.
The trick to adapt this Clustering metric to OCL is to consider each Object as a Cluster and every pixel as an data observation: basically each pixel is assigned to an Object (i.e. a cluster) using the object mask in which has the highest value (for example if pixel [3, 10] has value 0.1 for object 1, 0.5 for object 2 and 0.4 for object 3 therefore this pixel is assigned to “cluster 2”)
Model Architectures
At the moment of this article there isn’t a predominant model architecture but many different that works well, for example we have:
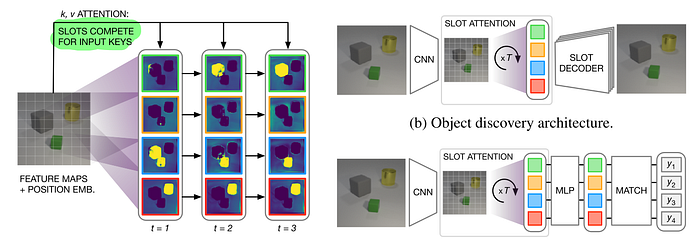
- Slot Attention introduce an Attention Mechanism along with a recurrent process to accurately estimate the latent space of each object followed by a standard decoder to get the mask and the object image
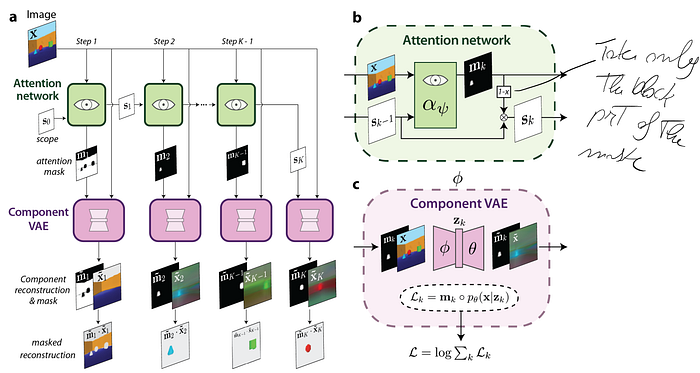
- MONet uses an UNet to get the masks for each object followed by a Variational AutoEncoder to get the objects reconstructed images and object latent space
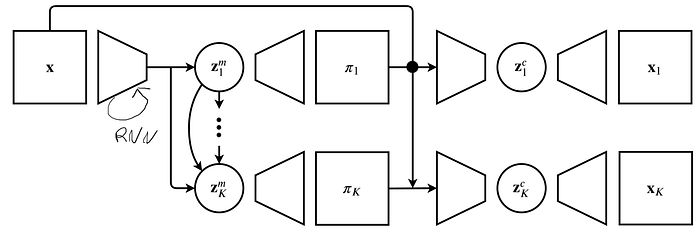
- GENESIS has a Variational AutoEncoder to estimate the masks of each object followed by another VAE that receive in input the image and the component mask to get the object image and the latent space
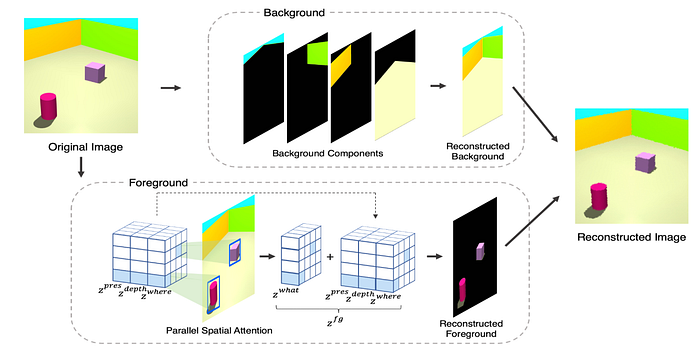
- SPACE models the foreground with bounding boxes while the background is modeled as a set of K objects
References
- Deepmind collection of Object Centric Learning Datasets: https://github.com/deepmind/multi_object_datasets (Multi-dsprites, Objects Room, CLEVR, Tetrominoes)
- Burgess, C. et al. “MONet: Unsupervised Scene Decomposition and Representation.” ArXiv abs/1901.11390 (2019)
- Engelcke, Martin et al. “GENESIS: Generative Scene Inference and Sampling with Object-Centric Latent Representations.” ArXiv abs/1907.13052 (2020): n. pag.
- Locatello, Francesco et al. “Object-Centric Learning with Slot Attention.” ArXiv abs/2006.15055 (2020): n. pag.
- Lin, Z. et al. “SPACE: Unsupervised Object-Oriented Scene Representation via Spatial Attention and Decomposition.” ArXiv abs/2001.02407 (2020): n. pag.
